本文共 3032 字,大约阅读时间需要 10 分钟。
对于有向图D=(V,A),如果V中有一发点(源)Vs,一收点(汇)Vt,其余均为中间节点,且对A中的每条弧均有权W(Vi,Vj)(简记为Wij,并称为弧容量),则称这样的赋权有向图D为容量网络,记为D=(V,A,W),通过D中弧(Vi,Vj)的物流量为fij,称为弧(Vi,Vj)的流量。所有弧上流量的集合f={fij}称为该网络D的一个流。
最大流最小割定理(max flow/min cut theory)
任一网络D中,最大流的流量=最小截集的截量
什么是流(flow)
在一个有向图中,只有出去的边没有进来的边的节点叫做源(source),只有进来的边没有出去的边的节点叫做汇(sink),其它的节点进来的边和出去的边应该是平衡的。
边上可以加权值,假设对于一个交通图来说,可以认为边上的权重为一条道路上的最大流量。那么对于图中任意两个节点来说,它们之间可以存在很多路径,每条路径上可以负载的最大流量应该是这条路径上权重最小的那条边所能承载的流量(联想一下“瓶颈”这个词,或者木桶理论),那么所有的路径上所负载流量之和也就是这两个节点之间多能通过的最大流了。
什么是割?
对于一个图中的两个节点来说,如果把图中的一些边去掉,刚好让他们之间无法连通的话,这些被去掉的边组成的集合就叫做割了,最小割就是指所有割中权重之和最小的一个割。
最大流最小割定理(max flow/min cut theory):对于任意一个只有一个源和一个汇的图来说,从源到汇的最大流等于最小割。
For any network having a single origin and single destination node, the maximum possible flow from origin to destination equals the minimum cut value for all cuts in the network.
这篇文章说的是Yuri Boykov and Vladimir Kolmogorov在2004年提出的一种基于增广路径的求解最大流最小割的算法,号称大部分情况下会很快。而且在算完之后,会自动完成最小割集的构造。
作者写了一个C的实现:
文章参考:《GRAPH BASED ALGORITHMS FOR SCENE RECONSTRUCTION FROM TWO OR MORE VIEWS》这是作者的博士论文,在最后的一章节里详细提到了这种算法的思路。
这个算法的思路并不难懂,但是看起来有点难度。文中充满了q is children of p之类的表述,看着看着就混淆了。而且代码里的变量命名也很随意,花了3,4天的时间,终于搞定。
算法的直观理解
第一个改进:
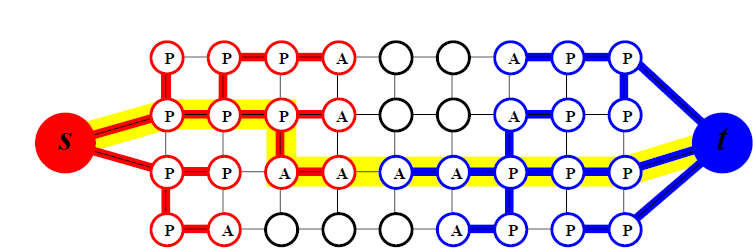
首先算法采用了两条增广路径,分别从source和sink出发,边搜索边标号,这样当所有的点都被搜索并标号后,最小割集也就形成了。
所有在最前沿的点称为active node,这些点的任务是去发展新的node。而被active node包围起来的那些点,则称之为passive node。
而没有被发掘出来的点则称之为free node。
第二个改进:
基于增广路径的算法都是遵循:找出一个可行流----》更新残留网络----》然后再找下一个可行流。
此算法需要不断地去找可行流,而每次找都得从源点重新开始进行一个广度遍历或者深度遍历直到找到汇点。这篇文章的算法正是基于此来进行改进。
找到一个可行流后,要进行augmention,然后必然会出现饱和的边,比如这样的一条路中:p1----->p2---->p3----->p4,p2->p3这条边饱和了。如果我们不管他,还是继续遍历去寻找汇点,那么当你再次找到一条路后,那么这条路中就有可能包含一些已经饱和路径,那就没法进行增广了。所以,我们必须要去调整那些饱和的边,使得在已经构建的路径中不存在饱和的边。在本例中,p3称之为orphan(孤点),那么接下来就得做一个adopt orphan的操作,呵呵,名字起得很有意思(养育孤儿),意思就是说给每个p3这样的孤儿点找一个新的parent,养育完就没有orphan存在了。方法如下:
检查p3的neighbors,看看有没有一个neighbor, let's say node q,s.t.
(1). q->p3满足容量大于0
(2). q是已经被搜过的点,也就是说q已经在我们的span tree了,in another word,当我们沿着汇点逆流而上搜索到q时,可以顺利地找到q的father,从而最终可以顺藤摸瓜摸到source上。
(3). 通过q最终能到达source或者sink这样的终点。这是因为有可能顺着q走着走着,最终走到一个free node去了。或者走到一个orphan去了,而这个orphan最终也无人抚养而变成free node。
那么如果找不到这样的q,那么p3就不得不变成free node。然后再做以下两个调整:
(4). 对于p3的邻居pk,如果pk到p3的边(pk-->p3)的容量大于0, 则将pk设为active。
(5). 对于p3的邻居ph,如果p3=parent(ph),那么把ph也设置为orphan,加入到orphan集合里。
这是因为当有一条路从sink走到ph的时候,会发现无路可走了,因为parent(ph)是一个free node!
所以我们必须对ph也做相同的处理,要么找一个新的parent,要么您老人家变成free node,先一边凉快会!
orphan集合中在增广时建立,每次更新一个边后,如果发现改变后的边的残留流量=0,则把边指向的那个点加入orphan set。
在adoption阶段,反复从orphan set中取点,每取出一个孤儿,首先看看能不能找到一个新的parent,如果找不到则令其变成free node,并把他的child变成orphan,加入到orphan集合中。循环往复,直到orphan set = 空集。
细节:
对上述的(3)可以进行优化。
优化一:不必每次要追溯到source/sink才罢休。
因为对于orphan的每一个邻居进行判断其是否originate from TERMINATE node时,都要逆流追溯至source / sink点。那么其中的一些点可能要被追溯多次,那么这是一个重复的操作。如果一个点,已经被证明了,他是可以到达source / sink的,那么下次当有点经过他的时候,他就可以直接告诉该点,OK,哥们歇歇吧,你是valid的,通过我可以追溯到source/sink。这就是在algorithm tunning里提到的mark的意思。
优化二:选择离source/sink最近的那个neighbor,作为orphan的新parent.
要实现这个优化,必须给每个节点附加一个属性:该节点到source/sink的最短距离。
并且在growth阶段,当一个active node q1 遇到另一个active node q2时,要比较一下是否把parent(q2)=q1后,q2到source/sink的距离更短,如果是,那么就调整下q2,使得它变成q1的child。正所谓:
人往高处走,水往低处流,节点都往终点凑
转载地址:http://cihxi.baihongyu.com/